Building a RAG System from Scratch: What the Research Says and How to Implement It
Written by
Jay Kim
A research-backed guide to building Retrieval-Augmented Generation systems — from the foundational 2020 paper to production-ready Python code. Covers chunking strategies, embeddings, hybrid search, re-ranking, Self-RAG, CRAG, and evaluation with RAGAS.
Introduction
If you've tried using a large language model for anything beyond casual conversation, you've likely encountered the same frustrating problem: the model confidently tells you something that is completely wrong. It hallucinates a citation that doesn't exist, and sometimes it references an event that never happened. It mixes up details from different sources into a plausible-sounding but fabricated answer.
It's a fundamental limitation, not a bug. LLMs are trained on a static snapshot of the internet, and once training ends, their knowledge is frozen. They can't access your company's internal documentation, they don't know about yesterday's product update, and they have no way to verify whether what they're saying is actually true.
Retrieval-Augmented Generation (RAG) was introduced to solve exactly this problem. Instead of relying solely on what a model memorized during training, RAG gives the model the ability to look things up, so that it can retrieve relevant documents from an external knowledge base and use them as context when generating a response.
Over the past few years, a significant body of research has emerged around making RAG systems actually work well: how to chunk documents, which embeddings to use, when retrieval helps versus when it hurts, and how to evaluate the whole pipeline.
In this article, I'll walk through what the research says about each of these decisions, and then we'll build a complete RAG system from scratch in Python. By the end, you'll have both the theoretical grounding and the working code to build your own.
The Problem: Why LLMs Need External Knowledge
Before diving into RAG, it's worth understanding precisely why LLMs fail in the ways they do.
Large language models are, at their core, next-token predictors. During training, they compress vast amounts of text into their parameters, learning statistical patterns about how language works and what facts tend to appear together. But this compression is lossy. The model doesn't store a faithful database of facts, it stores a probability distribution over sequences of tokens. When you ask it a factual question, it's not "looking up" the answer; it's generating the most likely continuation of your prompt based on patterns it learned.
This leads to three well-documented failure modes. First, knowledge cutoff: the model simply doesn't know about anything that happened after its training data was collected. Second, hallucination: when the model doesn't have strong enough signal to generate a correct answer, it generates a plausible-sounding one instead. Third, lack of attribution: even when the model is correct, it typically can't tell you where it learned the information, making it impossible to verify.
The 2023 paper from Huang et al., "A Survey of Hallucination in Natural Language Generation" (https://arxiv.org/abs/2202.03629), provides an extensive taxonomy of these failures and documents how they persist even in the largest models. The key insight is that scaling alone doesn't solve hallucination, a 175B parameter model hallucinates differently than a 7B model, but it still hallucinates.
RAG offers an elegant alternative: rather than trying to stuff all knowledge into the model's parameters, give the model access to external knowledge at inference time and let it synthesize information from retrieved documents into a coherent response.
The Original RAG Paper
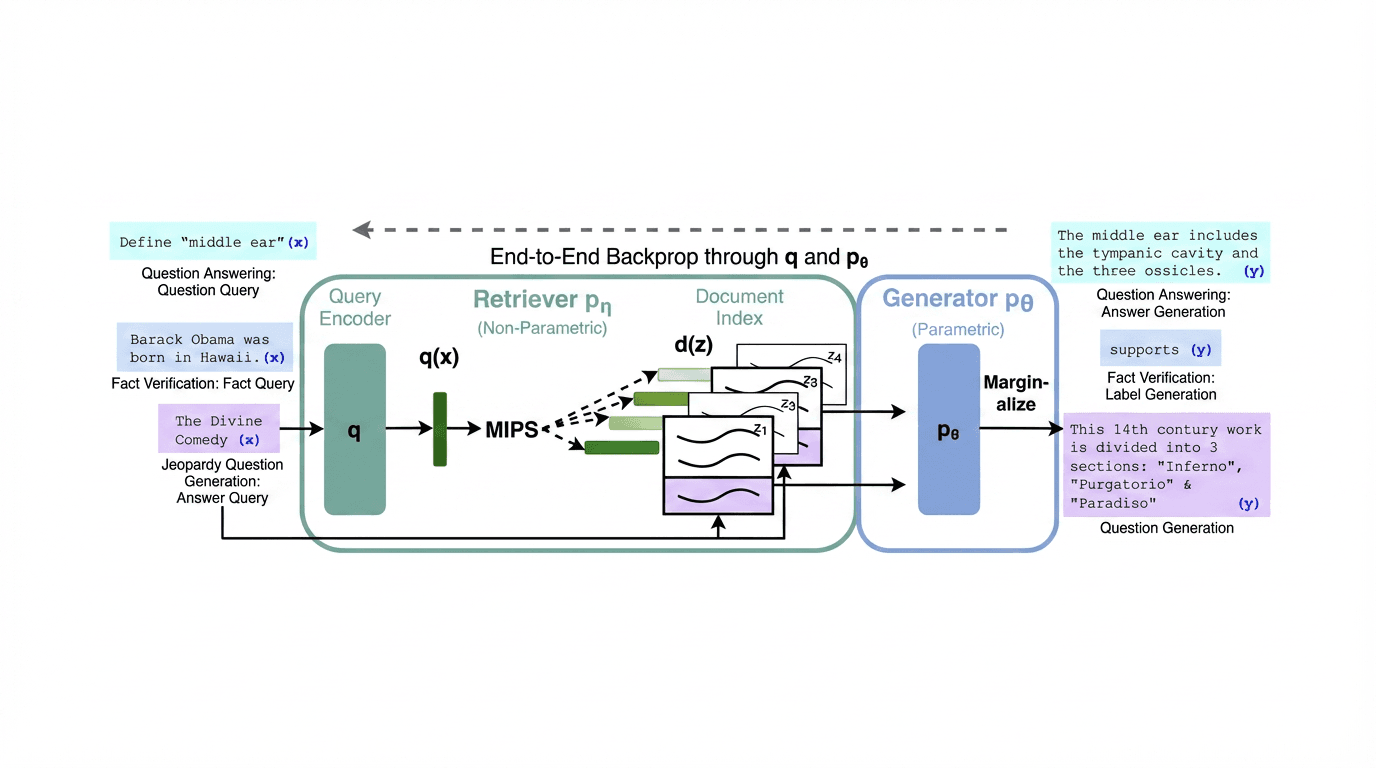
The term "Retrieval-Augmented Generation" was introduced by Lewis et al. at Facebook AI Research in their 2020 paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (https://arxiv.org/abs/2005.11401).

The architecture is composed of two components: a retriever (based on Dense Passage Retrieval, or DPR) and a generator (based on BART). When a query comes in, the retriever encodes it into a dense vector, performs maximum inner product search (MIPS) against a pre-built index of Wikipedia passages, retrieves the top-k most relevant documents, and then concatenates them with the original query before feeding everything to the generator.
The paper proposed two variants. RAG-Sequence uses the same retrieved documents to generate the entire output sequence, meaning all retrieved passages inform every token. RAG-Token can use different documents for each token generated, allowing the model to synthesize across sources at a more granular level.
The results were striking. RAG outperformed purely parametric models (models relying only on their trained weights) on open-domain question answering, fact verification, and knowledge-intensive generation tasks. On Natural Questions, RAG achieved 44.5 exact match, compared to 36.6 for a closed-book model of similar size. Perhaps more importantly, RAG's answers were more factual and more specific, with human evaluators preferring RAG outputs for their groundedness.
What made this paper foundational wasn't just the performance numbers — it was the demonstration that you could treat the retrieval component as a differentiable module and train the whole system end-to-end. The retriever wasn't a bolted-on hack; it was an integral part of the architecture.
From Naive RAG to Advanced RAG to Modular RAG
The original RAG paper established the paradigm, but the field has evolved significantly since 2020. A comprehensive survey by Gao et al., "Retrieval-Augmented Generation for Large Language Models: A Survey" (https://arxiv.org/abs/2312.10997), categorizes the evolution into three stages: Naive RAG, Advanced RAG, and Modular RAG.

Naive RAG is the straightforward "retrieve then generate" approach. You take a user query, retrieve documents from a vector store, stuff them into the prompt, and generate a response. This is what most tutorials teach, and it works surprisingly well for simple use cases. But it has well-documented failure points: the retriever might fetch irrelevant documents, the chunks might be too large or too small to contain the right information, and the generator might ignore the retrieved context or fail to synthesize across multiple documents.
Advanced RAG introduces optimizations at three stages of the pipeline. Pre-retrieval optimizations include better chunking strategies, query rewriting, and query expansion. Retrieval optimizations include hybrid search (combining dense and sparse retrieval), re-ranking retrieved results, and metadata filtering. Post-retrieval optimizations include compressing or summarizing retrieved documents before passing them to the generator, and prompt engineering to help the model use the context more effectively.
Modular RAG goes further by treating the entire pipeline as a set of interchangeable modules. Instead of a fixed "retrieve → generate" flow, you might have a router that decides whether retrieval is even necessary, a module that iteratively retrieves and refines, or a critic module that evaluates whether the retrieved documents are actually helpful before passing them to the generator.

Key Component #1: Chunking Strategies
The first decision in any RAG system is how to split your documents into chunks. This seems trivial but has a surprisingly large impact on retrieval quality.
The fundamental tension is between granularity and context. Small chunks (100–200 tokens) are more precise — when a chunk matches a query, it's likely to contain exactly the relevant information. But small chunks lose context — a sentence fragment about "the treatment" means nothing without knowing which treatment is being discussed. Large chunks (1000+ tokens) preserve context but dilute the signal, a large chunk might match a query because of one relevant sentence buried among nine irrelevant ones.
Research from Llamaindex's chunking evaluation (widely cited in the RAG literature) found that the optimal chunk size is task-dependent, but recursive character splitting with overlap tends to outperform naive fixed-size splitting across most benchmarks.
The most common strategies are:
Fixed-size chunking splits text into equal-sized pieces, typically with some overlap (e.g., 512 tokens with 50-token overlap). It's simple and fast but doesn't respect document structure.
Recursive character splitting (used in LangChain's RecursiveCharacterTextSplitter) tries to split on natural boundaries — first by paragraph (\n\n), then by sentence (\n), then by word — keeping chunks under a maximum size. This tends to produce more semantically coherent chunks.
Semantic chunking uses an embedding model to detect topic shifts within a document and splits at points where the semantic similarity between adjacent sentences drops. This is more expensive but produces the most meaningful chunks.
Document-structure-aware chunking uses markdown headers, HTML tags, or other structural elements to split documents along their natural hierarchy. If your documents have clear structure, this is often the best approach.
Key Component #2: Embeddings and Retrieval
Once your documents are chunked, you need to embed them into vectors and store them in a way that enables fast similarity search. The choice of embedding model is one of the most consequential decisions in a RAG pipeline.
The Sentence-BERT paper by Reimers and Gurevych (https://arxiv.org/abs/1908.10084) introduced the idea of using a siamese network architecture to produce fixed-size sentence embeddings that capture semantic similarity. Before this, using BERT for semantic search required encoding every query-document pair through the full model, which was computationally prohibitive.

The field has progressed rapidly since then. The Massive Text Embedding Benchmark (MTEB) by Muennighoff et al. (https://arxiv.org/abs/2210.07316) established a standardized evaluation framework covering 8 embedding tasks across 58 datasets. It showed that no single model dominates all tasks, and the best model depends on your specific use case.

A particularly interesting development is Matryoshka Representation Learning (MRL) by Kusupati et al. (https://arxiv.org/abs/2205.13147), which trains embeddings such that you can truncate them to smaller dimensions with minimal loss of quality. This means you can use 256-dimensional embeddings instead of 1024-dimensional ones, reducing storage and search costs significantly while retaining most of the semantic information.


For retrieval itself, the research consistently shows that hybrid search — combining dense (embedding-based) retrieval with sparse (keyword-based) retrieval like BM25 — outperforms either approach alone. Dense retrieval excels at semantic matching ("What causes headaches?" matching a document about "cephalalgia etiology"), while sparse retrieval excels at exact keyword matching (specific names, codes, identifiers). Combining them covers both bases.
Key Component #3: Re-ranking
Raw retrieval, whether dense, sparse, or hybrid, returns a ranked list of candidate documents, but the initial ranking is often imperfect. Re-ranking models provide a second pass that significantly improves precision.
The difference between retrieval and re-ranking is fundamental. Retrieval models (bi-encoders) encode the query and each document independently, then compare vectors. This is fast but limited — the model never sees the query and document together. Re-ranking models (cross-encoders) take the query-document pair as a single input and produce a relevance score. This is much slower but much more accurate because the model can attend to fine-grained interactions between the query and document.
Research from Nogueira and Cho, "Passage Re-ranking with BERT" (https://arxiv.org/abs/1901.04085), showed that even a basic BERT cross-encoder re-ranker improved MRR@10 on MS MARCO by over 12 points compared to BM25 alone. The typical pattern in production RAG systems is to retrieve a larger set (say, top 20–50 results) with a fast bi-encoder, then re-rank to select the top 3–5 with a cross-encoder.
Self-RAG: Teaching the Model When to Retrieve
One of the most important recent advances is Self-RAG by Asai et al. (https://arxiv.org/abs/2310.11511), which addresses a fundamental flaw in naive RAG: not every query needs retrieval, and sometimes retrieved documents hurt more than they help.

Self-RAG trains the language model to generate special "reflection tokens" that control the retrieval process. When the model encounters a query, it first generates a [Retrieve] token indicating whether retrieval would be helpful. If retrieval is triggered, the model evaluates each retrieved passage with an [IsRelevant] token. After generating a response segment, it emits [IsSupported] and [IsUseful] tokens to self-assess the quality of its own output.
The results are compelling. Self-RAG outperformed both standard RAG and Llama 2 (without retrieval) across six tasks, including open-domain QA, reasoning, and fact verification. On PopQA, Self-RAG achieved 55.8% accuracy compared to 36.7% for standard RAG with ChatGPT. More importantly, it retrieved passages for only 40-80% of queries (depending on the task), demonstrating that selective retrieval is better than always-retrieve approaches.

Corrective RAG: What to Do When Retrieval Fails
Corrective RAG (CRAG) by Yan et al. (https://arxiv.org/abs/2401.15884) tackles a complementary problem: even when you decide to retrieve, the retrieved documents might be wrong or insufficient. CRAG introduces a retrieval evaluator that assesses the quality of retrieved documents and takes one of three actions: if the documents are relevant, proceed normally; if the documents are ambiguous, refine the query and try again; if the documents are irrelevant, fall back to web search.

The evaluator is a lightweight classifier that scores each retrieved document for relevance. Based on a confidence threshold, it routes the pipeline through different paths. This is a form of the "Modular RAG" concept discussed earlier, the pipeline adapts its behavior based on the quality of intermediate results.
The RETRO Architecture: Retrieval at Training Time
While most RAG systems bolt retrieval onto a pretrained model at inference time, DeepMind's RETRO paper by Borgeaud et al. (https://arxiv.org/abs/2112.04426) took a fundamentally different approach: bake retrieval into the model architecture itself, from pretraining onward.

RETRO splits the input into fixed-size chunks, retrieves nearest neighbors for each chunk from a massive database (2 trillion tokens of text), and uses a chunked cross-attention mechanism to integrate the retrieved information into the generation process. The remarkable finding was that a 7.5B parameter RETRO model matched the performance of a 25x larger model on several benchmarks, suggesting that retrieval can substitute for raw parameter count.
This has profound implications for efficiency: instead of training ever-larger models, you can train a smaller model with access to a large retrieval database and achieve comparable results at a fraction of the compute cost.
Building a RAG System from Scratch
Now let's build a complete RAG system. We'll start simple and iteratively add sophistication, mirroring the Naive → Advanced RAG progression from the research.
Instruction for the project
json# Hands-On RAG — 9-Step Walkthrough A from-scratch Retrieval-Augmented Generation pipeline you can build one cell at a time. By the end you'll have compared a **naive RAG baseline** against an **advanced RAG** (query rewrite → multi-query → hybrid search → cross-encoder rerank) and evaluated both with **RAGAS**. --- ## 1. Prerequisites - macOS / Linux / Windows (WSL) - **Python 3.10+** (tested on 3.11) - An **OpenAI API key** with a small credit balance (~$1 is plenty) - ~500 MB free disk (embedding + reranker models are downloaded on first run) --- ## 2. Project layout Create this directory structure: ``` rag-handson/ ├── .env # your secret key (never commit this) ├── data/ │ └── papers/ │ └── <your PDFs>.pdf ├── chroma_db/ # auto-created by Step 2 ├── requirements.txt └── steps.py # or steps.ipynb — the 9 cells ``` ```bash mkdir -p rag-handson/data/papers cd rag-handson ``` Drop any PDFs you want to index into `./data/papers/`. Don't have one handy? This downloads the original RAG paper (Lewis et al., 2020): ```bash curl -L -o ./data/papers/rag-lewis-2020.pdf "https://arxiv.org/pdf/2005.11401" ``` --- ## 3. Python environment Create and activate a virtual environment: ```bash python3.11 -m venv .venv source .venv/bin/activate # Windows: .venv\Scripts\activate ``` Create `requirements.txt`: ```txt langchain>=1.0 langchain-community>=0.4 langchain-openai>=1.0 langchain-huggingface>=1.0 langchain-chroma>=1.0 langchain-classic>=1.0 langchain-text-splitters>=1.0 langchain-core>=1.0 chromadb>=1.0 sentence-transformers>=3.0 pypdf>=4.0 tiktoken>=0.7 rank_bm25>=0.2.2 numpy pandas python-dotenv ragas>=0.4 datasets ``` Install: ```bash pip install --upgrade pip pip install -r requirements.txt ``` --- ## 4. Environment variables Create `.env` in the project root: ```bash cat > .env <<'EOF' OPENAI_API_KEY=sk-your-real-key-here EOF ``` Replace the placeholder with a real key from https://platform.openai.com/api-keys. > **Note for macOS Finder users:** dotfiles are hidden by default. Toggle visibility with `Cmd + Shift + .` in Finder, or just edit `.env` in your code editor (VS Code / Cursor shows it without the toggle). --- ## 5. Running the 9 cells You can use **either** of these: ### Option A — Jupyter notebook ```bash pip install jupyter jupyter notebook ``` Create a new notebook in the project root (`steps.ipynb`) and paste each of the 9 cells into its own cell. Run them top-to-bottom with **Shift + Enter**. ### Option B — Single Python script Paste all 9 cells into a file named `steps.py`, then: ```bash python steps.py ``` Either way, run the cells **in order** the first time — later cells reuse variables from earlier cells (`documents`, `chunks`, `vectorstore`, `bm25_retriever`, `reranker`, `naive_chain`). After the first full run you can rerun any individual cell in isolation. --- ## 6. What each step does | Step | What it builds | Time (first run) | |---|---|---| | **Setup** | Loads `.env`, verifies `OPENAI_API_KEY` | <1 s | | **1 — Load & Chunk** | Reads PDFs, splits into 512-char chunks with 50-char overlap | ~5 s | | **2 — Vector Store** | Embeds chunks with `all-MiniLM-L6-v2`, persists to Chroma on disk | ~30 s (model download) | | **3 — Naive RAG** | Top-k dense retrieval + GPT answer via `RetrievalQA` | ~5 s | | **4 — Hybrid Search** | Adds BM25, fuses with dense via Reciprocal Rank Fusion | <1 s | | **5 — Re-ranker** | Adds cross-encoder (`ms-marco-MiniLM-L-6-v2`) for 2nd-stage ranking | ~15 s (model download) | | **6 — Query Transform** | LLM-based query rewriting + decomposition | ~3 s | | **7 — Multi-Query** | Generate n variations + merge results with RRF | ~5 s | | **8 — RAGAS** | Evaluate faithfulness / relevancy / precision / recall | ~30 s | | **9 — Comparison** | Run naive vs. advanced on the same query and print RAGAS | ~1 min | --- ## 7. Common pitfalls - **`openai.RateLimitError: insufficient_quota`** — your OpenAI account has no credits. Add a balance at https://platform.openai.com/account/billing. - **`.env` not loaded** — make sure `load_dotenv()` is called (it is, in Setup) and that `.env` sits in the **same directory** from which you run the script. - **`No PDFs found in ./data/papers/`** — the Step 1 loader uses `glob="*.pdf"` (non-recursive). Put PDFs directly in `./data/papers/`, not in sub-folders. - **`Vector store has more vectors than chunks`** — you re-indexed on top of an existing store. Delete `./chroma_db/` and rerun Step 2, or call `create_vector_store(chunks, rebuild=True)`. - **Cross-encoder / HuggingFace download hangs** — slow network. You can set a token: `echo 'HF_TOKEN=hf_...' >> .env` for higher rate limits (optional). - **`ModuleNotFoundError: langchain.text_splitter`** — LangChain 1.x moved it. Use `from langchain_text_splitters import RecursiveCharacterTextSplitter` (already done in the cells). --- ## 8. What you should see at the end The pipeline answers `"What is Retrieval-Augmented Generation?"` with a faithful paragraph drawn from your indexed PDFs, followed by a RAGAS table similar to: ``` Mean scores: faithfulness: 1.0000 answer_relevancy: 0.8874 context_precision: 0.9750 context_recall: 1.0000 ``` These are LLM-judge metrics, so they'll vary by ~±0.1 between runs. Anything above ~0.8 on all four means a healthy pipeline. --- ## 9. Cleanup ```bash # drop the vector store to force a rebuild rm -rf ./chroma_db # remove Python env deactivate rm -rf .venv # revoke your OpenAI API key when done # -> https://platform.openai.com/api-keys ``` --- ## 10. File summary ``` rag-handson/ ├── .env # OPENAI_API_KEY=sk-... ├── .venv/ # Python virtual environment ├── requirements.txt # pinned dependencies ├── data/papers/ # your source PDFs ├── chroma_db/ # persisted vectors (auto-created) └── steps.py or steps.ipynb # the 9 cells ``` That's it. Run the 9 cells top-to-bottom and you've built a complete RAG system with hybrid retrieval, reranking, query transforms, and reference-based evaluation.
Setting Up the Environment
pythonpip install langchain langchain-community langchain-openai \ langchain-huggingface langchain-chroma langchain-classic \ langchain-text-splitters langchain-core \ chromadb sentence-transformers pypdf tiktoken rank_bm25 \ numpy pandas python-dotenv ragas datasets
pythonimport os from dotenv import load_dotenv load_dotenv() assert os.getenv("OPENAI_API_KEY"), "Set OPENAI_API_KEY in .env first" print("Env OK")
Step 1: Loading and Chunking Documents
We'll start by loading a set of PDF documents and chunking them using the recursive character splitter, the strategy that consistently performs well across the literature.
And also implement semantic chunking so we can compare approaches
pythonfrom langchain_community.document_loaders import PyPDFLoader, DirectoryLoader from langchain_text_splitters import RecursiveCharacterTextSplitter def load_documents(data_path: str) -> list: loader = DirectoryLoader(data_path, glob="*.pdf", loader_cls=PyPDFLoader) documents = loader.load() print(f"Loaded {len(documents)} pages from {data_path}") return documents def chunk_documents(documents, chunk_size=512, chunk_overlap=50): text_splitter = RecursiveCharacterTextSplitter( chunk_size=chunk_size, chunk_overlap=chunk_overlap, length_function=len, separators=["\n\n", "\n", ". ", " ", ""], ) chunks = text_splitter.split_documents(documents) print(f"Split {len(documents)} pages into {len(chunks)} chunks") if chunks: avg_len = sum(len(c.page_content) for c in chunks) / len(chunks) print(f"Avg chunk length: {avg_len:.0f} chars") return chunks documents = load_documents("./data/papers/") chunks = chunk_documents(documents, chunk_size=512, chunk_overlap=50)
Step 2: Creating Embeddings and a Vector Store
Now we embed our chunks and store them in ChromaDB. We'll use an open-source embedding model from Sentence Transformers so the entire pipeline can run locally.
pythonimport os from langchain_huggingface import HuggingFaceEmbeddings from langchain_chroma import Chroma def create_vector_store(chunks, persist_dir="./chroma_db", rebuild=False): embeddings = HuggingFaceEmbeddings( model_name="sentence-transformers/all-MiniLM-L6-v2" ) store_exists = os.path.isdir(persist_dir) and os.listdir(persist_dir) if store_exists and not rebuild: vectorstore = Chroma( persist_directory=persist_dir, embedding_function=embeddings ) print( f"Reusing existing vector store at {persist_dir} " f"({vectorstore._collection.count()} vectors). " f"Set rebuild=True to re-index." ) else: vectorstore = Chroma.from_documents( documents=chunks, embedding=embeddings, persist_directory=persist_dir, ) print(f"Vector store created with {vectorstore._collection.count()} vectors") return vectorstore, embeddings vectorstore, embeddings = create_vector_store(chunks)
Step 3: Naive RAG — The Baseline
Let's build the simplest possible RAG pipeline first. This corresponds to the "Naive RAG" stage from the research survey.
pythonfrom langchain_openai import ChatOpenAI from langchain_classic.chains import RetrievalQA from langchain_core.prompts import PromptTemplate def build_naive_rag_chain(vectorstore): llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0) prompt = PromptTemplate( template="""Use the following context to answer the question. If you don't know the answer, say "I don't know." Don't make things up. Context: {context} Question: {question} Answer:""", input_variables=["context", "question"], ) return RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever(search_kwargs={"k": 5}), chain_type_kwargs={"prompt": prompt}, return_source_documents=True, ) naive_chain = build_naive_rag_chain(vectorstore) response = naive_chain.invoke({"query": "What is Retrieval-Augmented Generation?"}) print("Answer:", response["result"]) print("Sources:", len(response["source_documents"]), "chunks")
Step 4: Adding Hybrid Search (Dense + Sparse)
As the research shows, hybrid search consistently outperforms pure dense retrieval. Let's add BM25 sparse retrieval and combine it with our dense retriever.
pythonimport numpy as np from rank_bm25 import BM25Okapi class BM25Retriever: def __init__(self, chunks): self.chunks = chunks tokenized = [c.page_content.lower().split() for c in chunks] self.bm25 = BM25Okapi(tokenized) def retrieve(self, query, top_k=5): tokenized_query = query.lower().split() scores = self.bm25.get_scores(tokenized_query) top_indices = np.argsort(scores)[::-1][:top_k] return [(self.chunks[i], scores[i]) for i in top_indices] def hybrid_search(query, vectorstore, bm25_retriever, top_k=5, alpha=0.5): """Dense + BM25 fused with Reciprocal Rank Fusion.""" dense_results = vectorstore.similarity_search_with_score(query, k=top_k) sparse_results = bm25_retriever.retrieve(query, top_k=top_k) scores = {} for rank, (doc, _) in enumerate(dense_results): key = doc.page_content[:100] scores[key] = scores.get(key, 0) + alpha * (1 / (rank + 1)) for rank, (doc, _) in enumerate(sparse_results): key = doc.page_content[:100] scores[key] = scores.get(key, 0) + (1 - alpha) * (1 / (rank + 1)) all_docs = {d.page_content[:100]: d for d, _ in dense_results + sparse_results} ranked = sorted(scores.items(), key=lambda x: x[1], reverse=True) return [all_docs[k] for k, _ in ranked[:top_k]] bm25_retriever = BM25Retriever(chunks) hits = hybrid_search( "What is Retrieval-Augmented Generation?", vectorstore, bm25_retriever, top_k=3, ) for i, doc in enumerate(hits, 1): print(f"[{i}] {doc.page_content[:160]}...\n")
Step 5: Adding a Re-ranker
Now let's add a cross-encoder re-ranker to improve the precision of our retrieved results. This is the single biggest quality improvement you can make to a RAG pipeline.
pythonfrom sentence_transformers import CrossEncoder class Reranker: """Cross-encoder re-ranker for second-stage retrieval.""" def __init__(self, model_name="cross-encoder/ms-marco-MiniLM-L-6-v2"): self.model = CrossEncoder(model_name) def rerank(self, query, documents, top_k=3): """ Score each (query, document) pair with the cross-encoder and return the top-k documents by relevance. """ pairs = [(query, doc.page_content) for doc in documents] scores = self.model.predict(pairs) scored_docs = sorted( zip(documents, scores), key=lambda x: x[1], reverse=True ) print(f"Re-ranker scores (top {top_k}):") for doc, score in scored_docs[:top_k]: print(f" {score:.4f} — {doc.page_content[:80]}...") return [doc for doc, _ in scored_docs[:top_k]] # Usage: # reranker = Reranker() # candidates = hybrid_search(query, vectorstore, bm25_retriever, top_k=10) # top_docs = reranker.rerank(query, candidates, top_k=3)
Step 6: Query Transformation: Making Retrieval Smarter
One of the most effective Advanced RAG techniques is query transformation. The user's raw query is often not the best search query. Research shows that rewriting, decomposing, or expanding queries before retrieval significantly improves results.
pythonfrom langchain_openai import ChatOpenAI from langchain_core.prompts import PromptTemplate def rewrite_query(original_query: str) -> str: """ Use an LLM to rewrite the user's query into a better search query for retrieval. """ llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0) rewrite_prompt = PromptTemplate( template="""You are a search query optimizer. Rewrite the following user question into a clear, specific search query that will retrieve the most relevant documents. Return only the rewritten query. Original question: {question} Rewritten query:""", input_variables=["question"], ) chain = rewrite_prompt | llm result = chain.invoke({"question": original_query}) rewritten = result.content.strip() print(f"Original query: {original_query}") print(f"Rewritten query: {rewritten}") return rewritten def decompose_query(complex_query: str) -> list: """ Break a complex question into simpler sub-questions that can each be answered independently. """ llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0) decompose_prompt = PromptTemplate( template="""Break the following complex question into 2-4 simpler sub-questions that, when answered together, fully address the original. Return each sub-question on its own line, numbered. Complex question: {question} Sub-questions:""", input_variables=["question"], ) chain = decompose_prompt | llm result = chain.invoke({"question": complex_query}) sub_questions = [ line.strip().lstrip("0123456789.)") for line in result.content.strip().split("\n") if line.strip() ] print(f"Decomposed into {len(sub_questions)} sub-questions:") for sq in sub_questions: print(f" → {sq}") return sub_questions
Step 7: Implementing RAG with Multi-Query Retrieval
Let's put query transformation into practice with multi-query retrieval, generating multiple versions of the query, retrieving for each, and merging the results.
pythonfrom langchain_openai import ChatOpenAI from langchain_core.prompts import PromptTemplate def generate_multi_queries(original_query: str, n=3) -> list: """Generate multiple query variations for broader retrieval.""" llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.7) prompt = PromptTemplate( template="""Generate {n} different versions of the following question. Each version should approach the topic from a slightly different angle to help retrieve a broader set of relevant documents. Return each version on its own line, numbered. Original question: {question} Alternate versions:""", input_variables=["question", "n"], ) chain = prompt | llm result = chain.invoke({"question": original_query, "n": n}) queries = [ line.strip().lstrip("0123456789.)") for line in result.content.strip().split("\n") if line.strip() ] return [original_query] + queries[:n] def multi_query_retrieve( original_query, vectorstore, bm25_retriever, n_queries=3, top_k=5 ): """ Retrieve for multiple query variations and merge results using reciprocal rank fusion. """ queries = generate_multi_queries(original_query, n=n_queries) print(f"Retrieving for {len(queries)} query variations...") all_results = {} for qi, query in enumerate(queries): results = hybrid_search(query, vectorstore, bm25_retriever, top_k=top_k) for rank, doc in enumerate(results): key = doc.page_content[:100] if key not in all_results: all_results[key] = {"doc": doc, "score": 0} all_results[key]["score"] += 1 / (rank + 1) ranked = sorted(all_results.values(), key=lambda x: x["score"], reverse=True) merged = [item["doc"] for item in ranked[:top_k]] print(f"Merged into {len(merged)} unique documents") return merged
Step 8: Evaluating Your RAG System with RAGAS
Building a RAG system without evaluating it is like training a model without a test set. The RAGAS framework by Es et al. (https://arxiv.org/abs/2309.15217) provides automated metrics specifically designed for RAG evaluation.
RAGAS evaluates four dimensions. Faithfulness measures whether the generated answer is actually supported by the retrieved context (i.e., does the model hallucinate beyond what the documents say?). Answer relevance measures whether the answer actually addresses the question asked. Context precision measures whether the retrieved documents that are relevant appear near the top of the ranked list. Context recall measures whether all the information needed to answer the question was successfully retrieved.
pythonfrom ragas import evaluate from ragas.metrics import ( faithfulness, answer_relevancy, context_precision, context_recall, ) from ragas.llms import LangchainLLMWrapper from ragas.embeddings import LangchainEmbeddingsWrapper from langchain_openai import ChatOpenAI, OpenAIEmbeddings from datasets import Dataset import pandas as pd def evaluate_rag(questions, ground_truths, rag_chain, vectorstore): """ Evaluate a RAG pipeline using RAGAS (Es et al., arXiv:2309.15217). RAGAS provides reference-free metrics for RAG evaluation: - Faithfulness: is the answer supported by the retrieved context? - Answer Relevancy: does the answer address the question? - Context Precision: are relevant docs ranked near the top? - Context Recall: was all needed information retrieved? """ answers = [] contexts = [] for query in questions: response = rag_chain.invoke({"query": query}) answers.append(response["result"]) contexts.append([doc.page_content for doc in response["source_documents"]]) # Build the evaluation dataset eval_dataset = Dataset.from_dict( { "question": questions, "answer": answers, "contexts": contexts, "ground_truth": ground_truths, } ) ragas_llm = LangchainLLMWrapper(ChatOpenAI(model="gpt-4o-mini", temperature=0)) ragas_emb = LangchainEmbeddingsWrapper( OpenAIEmbeddings(model="text-embedding-3-small") ) result = evaluate( dataset=eval_dataset, metrics=[ faithfulness, answer_relevancy, context_precision, context_recall, ], llm=ragas_llm, embeddings=ragas_emb, ) # Example usage: # test_questions = [ # "What is Retrieval-Augmented Generation?", # "How does RAG reduce hallucinations?", # "What are the components of a RAG pipeline?", # ] # test_ground_truths = [ # "RAG combines retrieval with generation to ground LLM responses in external knowledge.", # "RAG reduces hallucinations by providing retrieved context that the LLM must stay faithful to.", # "A RAG pipeline consists of a retrieval module and an LLM-based generation module.", # ] # scores = evaluate_rag(test_questions, test_ground_truths, chain, vectorstore)
Step 9: Comparing Naive vs. Advanced RAG
Let's put it all together and compare our two pipelines side by side.
pythonimport os from dotenv import load_dotenv def run_comparison(): load_dotenv() DATA_PATH = "./data/papers/" if not os.getenv("OPENAI_API_KEY"): print("[error] Set OPENAI_API_KEY in your .env file first.") return # --- Shared setup --- documents = load_documents(DATA_PATH) if not documents: print(f"No PDFs found in {DATA_PATH}. Drop some PDFs there and re-run.") return chunks = chunk_documents(documents, chunk_size=512, chunk_overlap=50) vectorstore, _ = create_vector_store(chunks) bm25_retriever = BM25Retriever(chunks) reranker = Reranker() query = "What is Retrieval-Augmented Generation?" # --- NAIVE RAG --- print("\n" + "=" * 60) print("NAIVE RAG") print("=" * 60) naive_chain = build_naive_rag_chain(vectorstore) naive_response = naive_chain.invoke({"query": query}) print(f"Answer: {naive_response['result']}") print(f"Sources: {len(naive_response['source_documents'])} chunks") # --- ADVANCED RAG --- print("\n" + "=" * 60) print("ADVANCED RAG (hybrid + re-rank + query rewrite)") print("=" * 60) # 1. Rewrite query better_query = rewrite_query(query) # 2. Multi-query + hybrid search candidates = multi_query_retrieve( better_query, vectorstore, bm25_retriever, n_queries=3, top_k=10 ) # 3. Re-rank top_docs = reranker.rerank(better_query, candidates, top_k=3) # 4. Generate with top docs as context llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0) context = "\n\n".join([doc.page_content for doc in top_docs]) advanced_prompt = PromptTemplate( template="""Use the following context to answer the question. If you don't know the answer, say "I don't know." Don't make things up. Context: {context} Question: {question} Answer:""", input_variables=["context", "question"], ) chain = advanced_prompt | llm advanced_response = chain.invoke({"context": context, "question": query}) print(f"Answer: {advanced_response.content}") print(f"Sources: {len(top_docs)} re-ranked chunks") # --- RAGAS COMPARISON --- print("\n" + "=" * 60) print("RAGAS EVALUATION") print("=" * 60) test_questions = [ "What is Retrieval-Augmented Generation?", "How does RAG reduce hallucinations?", ] test_ground_truths = [ "RAG combines retrieval with generation to ground LLM responses in external knowledge.", "RAG reduces hallucinations by providing retrieved context the LLM must stay faithful to.", ] print("\nNaive RAG scores:") evaluate_rag(test_questions, test_ground_truths, naive_chain, vectorstore) if __name__ == "__main__": run_comparison()
What the Research Tells Us About When NOT to Use RAG
It's worth noting that RAG is not always the answer. The research literature identifies several cases where RAG underperforms alternatives.
When the required knowledge is already well-represented in the model's training data, RAG adds latency and complexity without improving accuracy. If you're asking GPT-4 to explain basic physics or summarize well-known historical events, retrieval is unnecessary overhead.
When the task requires deep reasoning over a large body of text rather than looking up specific facts, RAG's chunk-based retrieval can actually fragment the information the model needs. For tasks like "analyze the themes across all of Shakespeare's tragedies," you need the full context, not a handful of 512-token chunks.
When your documents are highly structured (databases, spreadsheets, APIs), text-to-SQL or tool-use approaches are usually more appropriate than embedding and retrieving text chunks.
The LIMA paper's famous finding — "Less Is More for Alignment" (https://arxiv.org/abs/2305.11206) — suggests a parallel lesson for RAG: sometimes a small amount of high-quality, carefully curated data in a fine-tune outperforms a large retrieval corpus of mixed quality.
Practical Recommendations from the Literature
Based on the research covered in this article, here are concrete recommendations for building RAG systems in practice.
For chunking, start with recursive character splitting at 512 tokens with 50-token overlap. If your documents have clear structure (markdown, HTML), use structure-aware splitting. Only invest in semantic chunking if you have diverse, unstructured documents and have verified that simpler methods underperform.
For embeddings, use BAAI/bge-large-en-v1.5 or intfloat/e5-large-v2 if quality is the priority, or all-MiniLM-L6-v2 if speed and memory are constraints. Check the MTEB leaderboard for the latest rankings, as this field moves fast.
For retrieval, always use hybrid search (dense + BM25) unless you have a strong reason not to. The marginal implementation cost is tiny and the quality improvement is consistent across the literature.
For re-ranking, add a cross-encoder re-ranker. Retrieve broadly (top 20-50) and re-rank narrowly (top 3-5). This two-stage approach gives you the speed of bi-encoders with the accuracy of cross-encoders.
For query transformation, implement multi-query generation for complex questions. It's a simple change that meaningfully improves recall.
For evaluation, use RAGAS or a similar framework from the start. Without evaluation, you're optimizing blind. Track faithfulness (are answers grounded?) and context recall (is the right information being retrieved?) as your primary metrics.
Conclusion
RAG has evolved rapidly from the original 2020 paper to today's sophisticated multi-stage pipelines. The core insight remains the same, giving language models access to external knowledge at inference time produces more accurate, more verifiable, and more up-to-date responses. But the research has taught us that how you implement each component matters enormously.
The progression from Naive RAG to Advanced RAG is not just an academic taxonomy. Each improvement such as hybrid search, re-ranking, query transformation, self-reflection addresses a specific, documented failure mode. The papers cited throughout this article provide the empirical evidence for why each of these components matters, and the code above gives you a working implementation of each one.
If you're building a RAG system today, start with the naive approach, evaluate it properly with RAGAS, identify where it fails, and add sophistication where the evaluation tells you it's needed. The research gives you the menu of techniques; evaluation tells you which ones to order.
Paper References
- Lewis et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (2020) — https://arxiv.org/abs/2005.11401
- Gao et al., "Retrieval-Augmented Generation for Large Language Models: A Survey" (2023) — https://arxiv.org/abs/2312.10997
- Borgeaud et al., "Improving Language Models by Retrieving from Trillions of Tokens (RETRO)" (2021) — https://arxiv.org/abs/2112.04426
- Asai et al., "Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection" (2023) — https://arxiv.org/abs/2310.11511
- Yan et al., "Corrective Retrieval Augmented Generation (CRAG)" (2024) — https://arxiv.org/abs/2401.15884
- Reimers & Gurevych, "Sentence-BERT" (2019) — https://arxiv.org/abs/1908.10084
- Muennighoff et al., "MTEB: Massive Text Embedding Benchmark" (2022) — https://arxiv.org/abs/2210.07316
- Kusupati et al., "Matryoshka Representation Learning" (2022) — https://arxiv.org/abs/2205.13147
- Nogueira & Cho, "Passage Re-ranking with BERT" (2019) — https://arxiv.org/abs/1901.04085
- Es et al., "RAGAS: Automated Evaluation of Retrieval Augmented Generation" (2023) — https://arxiv.org/abs/2309.15217
- Huang et al., "A Survey of Hallucination in Natural Language Generation" (2022) — https://arxiv.org/abs/2202.03629


