Knowledge Distillation: How to Compress Large Models into Small Ones That Actually Work
Written by
Jay Kim
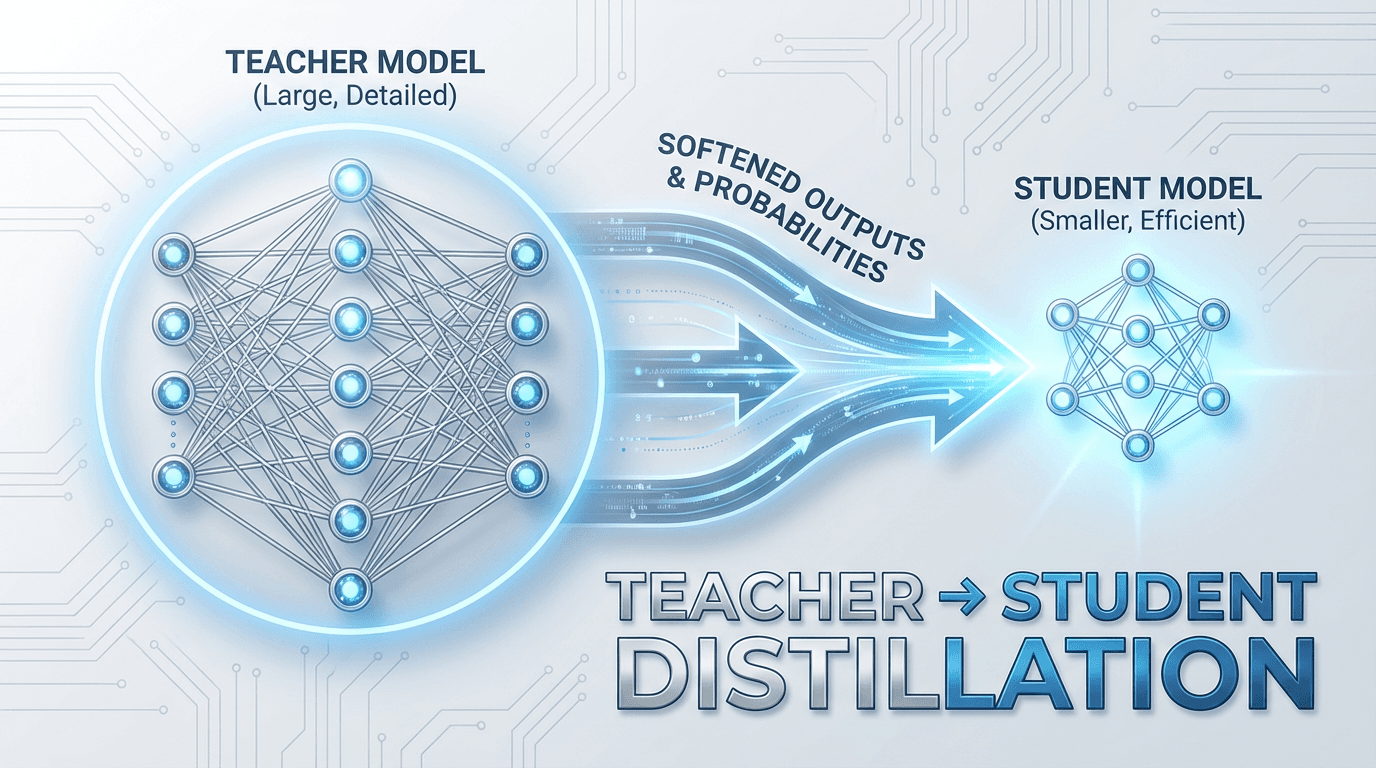
Your 70B model is brilliant but undeployable. Knowledge distillation transfers its dark knowledge — the rich information hidden in wrong answers — into a small model that runs fast, runs cheap, and actually works. This guide covers the theory, math, PyTorch code, LLM-specific techniques, and hard-won lessons for shipping compressed models in production.
A 70-billion-parameter behemoth that answers questions like a seasoned expert, classifies text with near-human accuracy, or generates code that actually compiles. There is just one problem: it costs a fortune to serve, takes seconds to respond, and absolutely will not fit on an edge device.
So you try the obvious thing. You train a smaller model from scratch on the same data. And the result is mediocre. The gap between your large model and the small one feels enormous. The accuracy drops. The nuance disappears. The small model makes confident, stupid mistakes that the large model never would.
This is where knowledge distillation enters the picture, not as a hack or a shortcut, but as a principled framework for transferring what a large model knows into a smaller model that can actually be deployed. It is one of the most important techniques in modern ML engineering, and if you are building anything that needs to run fast, run cheap, or run on-device, you need to understand it deeply.
The Core Idea: Learn from the Teacher, Not the Textbook
Traditional supervised learning is straightforward. You have inputs, you have ground-truth labels, and you train a model to map one to the other. The labels are "hard", a one-hot vector that says "this is a cat" and nothing else.
But think about what a large, well-trained model actually outputs. When it classifies an image of a Persian cat, it does not just say "cat." Its softmax output might assign 0.85 probability to "cat," 0.08 to "dog," 0.03 to "fox," and 0.02 to "lynx." That distribution is rich with information. It tells you that this particular image has some visual similarity to dogs and foxes. It encodes relationships between classes that the hard label completely ignores.
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean formalized this intuition in their 2015 paper, and Hinton called this extra information "dark knowledge", the knowledge embedded in the wrong answers. A model that assigns 0.08 to "dog" and 0.0001 to "airplane" is telling you something meaningful about the structure of the input space. This relational information is exactly what makes distillation more powerful than simply training on hard labels.
Knowledge distillation, then, is a teacher-student framework. The large model (the teacher) has already learned a rich internal representation of the data. The small model (the student) learns not from the raw labels, but from the teacher's outputs, its soft probability distributions, its intermediate representations, or both.
The Mathematics: Temperature, Soft Targets, and the Distillation Loss
The mathematical machinery of knowledge distillation is elegant and surprisingly simple.
Given an input x, the teacher model produces logits zt and the student model produces logits zs. To extract the dark knowledge from the teacher, we soften its output distribution using a temperature parameter T:

When T=1, this is the standard softmax. As T increases, the distribution becomes softer — probabilities spread out more evenly, and the relative differences between classes become more visible. At high temperatures, even low-probability classes get meaningful probability mass, and the student can learn finer-grained relationships.
The total distillation loss is typically a weighted combination of two terms:

The first term is the distillation loss — the KL divergence between the teacher's soft predictions and the student's soft predictions, both computed at temperature T. The T^2 factor compensates for the fact that gradients from soft targets are scaled by 1/T^2 relative to hard targets. The second term is the standard cross-entropy loss against the true hard labels, computed at T=1. The hyperparameter α controls the balance between learning from the teacher and learning from the ground truth.
In practice, α is usually set high (0.7–0.9), because the teacher's soft targets carry far more information per training example than the hard labels do. The temperature T typically ranges from 2 to 20, with values between 3 and 6 being a common sweet spot.
Why Distillation Works Better Than Training From Scratch
It might seem like the student should be able to learn the same thing from the original training data. But there are several reasons why learning from the teacher is fundamentally easier.
Information density. A hard label gives you 1 bit of information per class (correct or not). A soft distribution gives you a continuous signal across all classes. Every training example becomes exponentially more informative, which is especially critical when the student has limited capacity.
Implicit regularization. The teacher's soft targets smooth the label space. The student is less likely to overfit to noisy or mislabeled training examples because the teacher has already averaged out some of that noise through its own generalization. The soft distribution acts as a form of label smoothing — but a principled, data-dependent form rather than the naive uniform smoothing you might apply manually.
Relational knowledge. The teacher implicitly encodes metric structure. If class A is more similar to class B than to class C, the teacher's soft outputs will reflect that. The student learns not just the decision boundaries, but the geometry of the output space. This is particularly powerful in tasks with many classes, hierarchical class structures, or continuous output spaces.
Data efficiency. Because each example carries more signal, distillation often requires less training data than training from scratch. In some settings, you can distill effectively using only unlabeled data — just pass it through the teacher and use the teacher's predictions as targets. This unlocks massive unlabeled corpora that would otherwise be useless for supervised training.
Types of Knowledge Distillation
The original formulation focuses on matching the final output distributions, but the field has expanded significantly. There are three broad categories of distillation, and understanding when to use each one is critical for practical success.
Response-based distillation is the classic approach described above. The student mimics the teacher's final output layer — its soft probability distribution over classes (for classification) or its predicted values (for regression). This is the simplest to implement and requires no access to the teacher's internals. You only need to be able to query the teacher for predictions. This makes it applicable even when the teacher is a black-box API.
Feature-based distillation goes deeper. Instead of just matching outputs, the student is trained to match the teacher's intermediate representations — the activations at hidden layers. The intuition is that the teacher's internal features capture abstract, reusable patterns that the output layer alone cannot convey. FitNets, introduced by Romero et al. in 2015, were among the first to explore this direction. Because the teacher and student typically have different hidden dimensions, a small learned projection layer (called a "hint" layer) is used to align the representations. Feature-based methods often produce better students, but they require architectural compatibility and access to the teacher's internals.
Relation-based distillation is the most abstract form. Instead of matching specific activations or outputs, the student learns to preserve the relationships between examples as encoded by the teacher. For instance, if the teacher represents two inputs as being close in its feature space, the student should too. Methods like PKT (Probabilistic Knowledge Transfer) and relational knowledge distillation (RKD) formalize this using distance or angle relationships between pairs or triplets of examples. This approach is especially powerful when the teacher and student have very different architectures, because it does not require any layer-to-layer correspondence.
Distillation in the Age of LLMs
Knowledge distillation has been around since 2015, but the rise of large language models has made it more relevant than ever. Running a 70B-parameter model costs real money — on the order of dollars per hour on cloud GPUs — and latency matters for real-time applications. Distillation is one of the primary tools for making LLMs practical.
In the LLM context, distillation takes on some unique characteristics. The output space is a distribution over the entire vocabulary at every token position, which means the teacher provides an extremely rich signal. A teacher model generating a sentence doesn't just tell you the right next token — it tells you the probability of every token in the vocabulary, which encodes syntactic, semantic, and pragmatic information simultaneously.
There are two dominant paradigms for LLM distillation. White-box distillation requires access to the teacher's logits at every token position. You train the student to match the teacher's full output distribution using KL divergence, just as in the classic formulation. This is the most information-rich approach but requires running the teacher during training to produce logits, which is computationally expensive.
Black-box distillation uses only the teacher's generated text. You use the teacher to generate completions for a set of prompts, then fine-tune the student on these completions using standard supervised learning (cross-entropy on hard tokens). This is simpler and cheaper, but you lose the dark knowledge — the student only sees the teacher's top-1 token choices, not the full distribution. In practice, black-box distillation still works remarkably well, because the teacher's generated text is often higher quality than any human-written training data. Projects like Alpaca, Vicuna, and many open-source instruction-tuned models are essentially black-box distillations of GPT-4 or similar frontier models.
A more nuanced approach that has gained traction is on-policy distillation, where the student generates its own outputs, and then the teacher provides token-level or sequence-level feedback on the student's own generations. This avoids the train-test distribution mismatch that plagues purely offline approaches and tends to produce more robust students.
Practical Implementation: A PyTorch Walkthrough
Let us make this concrete. Here is how you implement vanilla response-based distillation in PyTorch for a classification task.
python"""DistillationLoss (PyTorch walkthrough) + sanity checks.""" import torch import torch.nn as nn import torch.nn.functional as F class DistillationLoss(nn.Module): def __init__(self, temperature=4.0, alpha=0.7): super().__init__() self.temperature = temperature self.alpha = alpha self.ce_loss = nn.CrossEntropyLoss() def forward(self, student_logits, teacher_logits, true_labels): # Soft target loss (KL divergence at temperature T) soft_teacher = F.softmax(teacher_logits / self.temperature, dim=-1) soft_student = F.log_softmax(student_logits / self.temperature, dim=-1) distill_loss = F.kl_div( soft_student, soft_teacher, reduction="batchmean" ) * (self.temperature**2) # Hard target loss (standard cross-entropy) hard_loss = self.ce_loss(student_logits, true_labels) # Combined loss return self.alpha * distill_loss + (1 - self.alpha) * hard_loss # --- checks --- torch.manual_seed(0) B, C = 8, 10 student_logits = torch.randn(B, C, requires_grad=True) teacher_logits = torch.randn(B, C) # teacher treated as fixed targets labels = torch.randint(0, C, (B,)) crit = DistillationLoss(temperature=4.0, alpha=0.7) loss = crit(student_logits, teacher_logits, labels) assert loss.ndim == 0 and torch.isfinite(loss), loss loss.backward() assert student_logits.grad is not None and torch.isfinite(student_logits.grad).all() # kl_div: input must be log-probs, target probs — matches walkthrough with torch.no_grad(): s = F.log_softmax(student_logits / 4.0, dim=-1) t = F.softmax(teacher_logits / 4.0, dim=-1) manual_kl = (t * (t.clamp_min(1e-12).log() - s)).sum(dim=-1).mean() * 16.0 assert torch.allclose( F.kl_div(s, t, reduction="batchmean") * 16.0, manual_kl, rtol=1e-4, atol=1e-4 ) print(f"Sample loss: {loss.item():.4f}") print("DistillationLoss OK — forward/backward and KL semantics verified.")
The training loop looks like any standard PyTorch training loop, with one addition: you run the teacher in inference mode to produce logits, then pass both teacher and student logits to the distillation loss.
python"""Cell 2 — Full KD training loop (teacher eval + student train), image-classification style.""" import torch import torch.nn as nn import torch.nn.functional as F from torch.utils.data import DataLoader, TensorDataset class DistillationLoss(nn.Module): def __init__(self, temperature=4.0, alpha=0.7): super().__init__() self.temperature = temperature self.alpha = alpha self.ce_loss = nn.CrossEntropyLoss() def forward(self, student_logits, teacher_logits, true_labels): soft_teacher = F.softmax(teacher_logits / self.temperature, dim=-1) soft_student = F.log_softmax(student_logits / self.temperature, dim=-1) distill_loss = ( F.kl_div(soft_student, soft_teacher, reduction="batchmean") * (self.temperature**2) ) hard_loss = self.ce_loss(student_logits, true_labels) return self.alpha * distill_loss + (1 - self.alpha) * hard_loss class MLP(nn.Module): def __init__(self, in_dim, hidden, num_classes): super().__init__() self.net = nn.Sequential( nn.Linear(in_dim, hidden), nn.ReLU(), nn.Linear(hidden, num_classes), ) def forward(self, x): return self.net(x) def make_synthetic_loaders(device, n_train=2000, n_test=500, in_dim=32, n_classes=5, seed=0): g = torch.Generator().manual_seed(seed) # Ground-truth linear rule + noise; teacher will overfit this structure w = torch.randn(in_dim, n_classes, generator=g) * 0.5 def pack(split_n): x = torch.randn(split_n, in_dim, generator=g) logits = x @ w + torch.randn(split_n, n_classes, generator=g) * 0.1 y = logits.argmax(dim=-1) return TensorDataset(x.to(device), y.to(device)) train_ds = pack(n_train) test_ds = pack(n_test) return ( DataLoader(train_ds, batch_size=64, shuffle=True), DataLoader(test_ds, batch_size=256, shuffle=False), ) device = torch.device("cpu") in_dim, n_classes = 32, 5 train_loader, test_loader = make_synthetic_loaders(device) # Teacher: wider hidden; pre-train briefly so student has something to distill teacher = MLP(in_dim, hidden=128, num_classes=n_classes).to(device) student = MLP(in_dim, hidden=32, num_classes=n_classes).to(device) opt_t = torch.optim.Adam(teacher.parameters(), lr=1e-2) for _ in range(80): for x, y in train_loader: opt_t.zero_grad() loss = F.cross_entropy(teacher(x), y) loss.backward() opt_t.step() teacher.eval() for p in teacher.parameters(): p.requires_grad_(False) distillation_criterion = DistillationLoss(temperature=4.0, alpha=0.7).to(device) optimizer = torch.optim.Adam(student.parameters(), lr=5e-3) # --- walkthrough-style loop --- student.train() for epoch in range(3): total = 0.0 for inputs, labels in train_loader: inputs, labels = inputs.to(device), labels.to(device) with torch.no_grad(): teacher_logits = teacher(inputs) student_logits = student(inputs) loss = distillation_criterion(student_logits, teacher_logits, labels) optimizer.zero_grad() loss.backward() optimizer.step() total += loss.item() * inputs.size(0) print(f"epoch {epoch+1} mean loss: {total / len(train_loader.dataset):.4f}") student.eval() correct, total = 0, 0 with torch.no_grad(): for x, y in test_loader: pred = student(x).argmax(dim=-1) correct += (pred == y).sum().item() total += y.size(0) acc = correct / total print(f"Student test accuracy: {acc:.3f}") assert acc > 0.5, "student should beat chance on this synthetic task" print("KD training loop OK.")
For LLM distillation at the token level, the structure is the same but applied to every token position in the sequence:
python"""LM-style token distillation loss (walkthrough) + masked variant note.""" import torch import torch.nn.functional as F def lm_distillation_loss(student_logits, teacher_logits, labels, T=3.0, alpha=0.8): """ student_logits: (batch, seq_len, vocab_size) teacher_logits: (batch, seq_len, vocab_size) labels: (batch, seq_len) — token IDs """ B, S, V = student_logits.shape student_flat = student_logits.reshape(-1, V) teacher_flat = teacher_logits.reshape(-1, V) labels_flat = labels.reshape(-1) # Soft loss soft_teacher = F.softmax(teacher_flat / T, dim=-1) soft_student = F.log_softmax(student_flat / T, dim=-1) distill_loss = F.kl_div(soft_student, soft_teacher, reduction="batchmean") * (T**2) # Hard loss (ignore padding tokens, typically -100) hard_loss = F.cross_entropy(student_flat, labels_flat, ignore_index=-100) return alpha * distill_loss + (1 - alpha) * hard_loss # --- walkthrough check: random LM tensors --- torch.manual_seed(1) B, S, V = 2, 8, 50 stu = torch.randn(B, S, V, requires_grad=True) tea = torch.randn(B, S, V) # mix real targets and padding lab = torch.randint(0, V, (B, S)) lab[:, 3:5] = -100 loss = lm_distillation_loss(stu, tea, lab, T=3.0, alpha=0.8) assert loss.ndim == 0 and torch.isfinite(loss), loss loss.backward() assert stu.grad is not None print(f"LM KD loss (with some -100 labels): {loss.item():.4f}") print( "Note: this walkthrough applies KL on *all* positions, including padding. " "Production code usually masks distill_loss to valid tokens only." ) def lm_distillation_loss_masked(student_logits, teacher_logits, labels, T=3.0, alpha=0.8): """Same as walkthrough but KL only where labels != -100 (recommended).""" B, S, V = student_logits.shape mask = labels.reshape(-1) != -100 sf = student_logits.reshape(-1, V)[mask] tf = teacher_logits.reshape(-1, V)[mask] lf = labels.reshape(-1)[mask] soft_teacher = F.softmax(tf / T, dim=-1) soft_student = F.log_softmax(sf / T, dim=-1) distill_loss = F.kl_div(soft_student, soft_teacher, reduction="batchmean") * (T**2) hard_loss = F.cross_entropy(sf, lf) return alpha * distill_loss + (1 - alpha) * hard_loss stu_m = torch.randn(B, S, V, requires_grad=True) loss_m = lm_distillation_loss_masked(stu_m, tea, lab) loss_m.backward() assert stu_m.grad is not None print(f"Masked LM KD loss: {loss_m.item():.4f}") print("LM distillation OK.")
Hyperparameter Tuning: What Actually Matters
Not all hyperparameters are created equal in distillation. Here is what moves the needle the most.
Temperature T is the most important hyperparameter. Too low (close to 1) and the soft targets collapse back to near-hard labels, wasting the dark knowledge. Too high and the distribution becomes nearly uniform, drowning out the meaningful signal. Start with T=4 and sweep over the range of 2 to 10. The optimal temperature often correlates with the number of classes — more classes tend to benefit from higher temperatures.
Alpha α controls the balance between teacher supervision and label supervision. In most settings, the teacher signal should dominate — start with α=0.7 and go up to 0.9. If your labels are noisy, push alpha higher to let the teacher's smoothed predictions take over. If your teacher is imperfect (e.g., trained on a different domain), lower alpha to keep the student grounded in the true labels.
Student architecture matters more than most people realize. A common mistake is making the student too small. If the capacity gap between teacher and student is too large, no amount of distillation will close it. A good rule of thumb is that the student should have at least 10–30% of the teacher's parameters to capture most of the teacher's performance. Going below that often results in diminishing returns. Depth tends to matter more than width — a deeper, narrower student usually outperforms a shallow, wider one with the same parameter count.
Training duration should be longer than you think. Students trained via distillation often benefit from longer training schedules than models trained on hard labels alone. The soft targets provide a denser gradient signal that the student can continue to extract value from well beyond the point where hard-label training would plateau.
Advanced Techniques and Modern Variants
The field has not stood still since 2015. Several important extensions have emerged that address limitations of the vanilla approach.
Self-distillation is the surprisingly effective technique of distilling a model into itself — using the model's own predictions from a previous training epoch (or a previous checkpoint) as soft targets. This acts as a form of progressive regularization and has been shown to improve performance even without any model compression. The Born-Again Networks paper demonstrated that a student with the identical architecture as the teacher can actually surpass the teacher's performance through distillation, which challenges the assumption that distillation is only useful for compression.
Multi-teacher distillation uses an ensemble of teachers rather than a single one. The student can be trained on the averaged soft targets from multiple teachers, which tends to produce a more robust and well-calibrated student. This is particularly useful when individual teachers have complementary strengths — one might be better at certain classes or domains than another.
Progressive distillation addresses the capacity gap problem by introducing intermediate-sized models. Instead of distilling directly from a very large teacher to a very small student, you create a chain: large teacher → medium assistant → small student. Each step bridges a smaller capacity gap, making each distillation step more efficient. This is related to the "teacher assistant" framework proposed by Mirzadeh et al.
Task-specific distillation adapts the approach for structured outputs. For object detection, you might distill not just the classification logits but also the bounding box regression outputs and the region proposal features. For machine translation, you might use sequence-level distillation, where the teacher generates full translations and the student is trained on those translations rather than the reference translations. Kim and Rush showed this to be remarkably effective for neural machine translation.
Quantization-aware distillation combines knowledge distillation with model quantization. The student is trained in a quantization-aware setting (simulating low-bit arithmetic during training) while receiving soft targets from a full-precision teacher. This produces models that are compressed in two ways simultaneously — fewer parameters and lower precision — and the distillation signal helps compensate for the quantization noise.
Common Pitfalls and How to Avoid Them
Having walked through the theory and the techniques, let me highlight the mistakes that derail distillation projects most often.
Using a bad teacher. This seems obvious, but it is worth stating: distillation cannot create knowledge from nothing. If your teacher is poorly trained, overfit, or miscalibrated, the student will faithfully learn the teacher's mistakes. Always validate the teacher thoroughly before starting distillation. Check not just its accuracy but its calibration — a well-calibrated teacher produces more useful soft targets.
Ignoring the domain gap. If your teacher was trained on a different data distribution than your target deployment domain, its soft targets may be misleading. In this case, reduce α\alphaα to rely more on hard labels from your target domain, or fine-tune the teacher on your domain data before distilling.
Matching the wrong things. For feature-based distillation, choosing which layers to match is critical. Matching too many layers overconstrains the student and hurts performance. Matching the wrong layers (e.g., early layers in the teacher to late layers in the student) introduces conflicting optimization signals. Start with matching only the last hidden layer and add more only if it helps.
Forgetting about data augmentation. Distillation and data augmentation are complementary. Augmented examples that might confuse a model trained on hard labels are handled gracefully when the teacher provides soft, nuanced targets. Combine aggressive augmentation with distillation for the best results.
Neglecting the student's own learning. Setting α=1.0 and ignoring the hard labels entirely sometimes works, but often the student benefits from some grounding in the true labels. This is especially true early in training, when the student's representations are random and the teacher's soft targets are not yet useful. Some practitioners use a curriculum where α\alphaα starts low and increases during training.
Real-World Impact: Where Distillation Ships
Knowledge distillation is not just a research curiosity. It powers production systems at massive scale.
Google used distillation to compress BERT into smaller models for on-device use and search ranking. The DistilBERT model from Hugging Face retains 97% of BERT's language understanding performance with 40% fewer parameters and 60% faster inference — a direct product of knowledge distillation. Apple uses distillation extensively to fit powerful models onto iPhones and Apple Watches, where power and compute budgets are measured in milliwatts. OpenAI's GPT-4o Mini and similar compact models from other labs are widely understood to involve distillation as part of their training pipeline.
In autonomous driving, distillation compresses expensive multi-sensor fusion models into lightweight models that can run within the strict latency budgets of real-time control systems. In recommendation systems, it transfers knowledge from massive offline models (trained on billions of interactions) into small online models that must score candidates in single-digit milliseconds.
When Not to Distill
Distillation is powerful, but it is not always the right tool. If your bottleneck is data quality rather than model size, distillation will not help — you need better data, not a smaller model. If the task is simple enough that a small model trained from scratch already achieves near-optimal performance, distillation adds complexity for little gain. And if you need the student to exceed the teacher's performance (rather than approximate it), you should look at techniques like self-training, iterative distillation, or reinforcement learning.
Distillation also introduces a dependency on the teacher at training time. If the teacher is a proprietary API, you are exposed to changes in the API's behavior, rate limits, and costs. If the teacher is an open model, you need the compute to run it during training — which, for a 70B teacher, is not trivial.
Conclusion
Knowledge distillation is the bridge between what we can train and what we can deploy. It is the reason a model that took a cluster of GPUs to train can run on your phone. It is why a 3B-parameter model can sometimes match a 70B model on specific tasks. And it is one of the few techniques in ML that is simultaneously well-understood theoretically, straightforward to implement, and massively impactful in practice.
The recipe is simple: train a big model, soften its outputs, and teach a small model to mimic them. The art is in the details — the temperature, the architecture, the data, the balance between teacher and ground truth. But the core insight remains as elegant as when Hinton first articulated it: the wrong answers carry knowledge too, and a student wise enough to listen to them will outperform one that only studies the answer key.
References
1. Distilling the Knowledge in a Neural Network (Hinton, Vinyals, Dean, 2015)
— The foundational paper on knowledge distillation. https://arxiv.org/abs/1503.02531
2. Knowledge Distillation: A Survey (Gou, Yu, Maybank, Tao, 2021)
— Comprehensive survey covering knowledge categories, training schemes, teacher-student architecture, distillation algorithms, performance comparison and applications.[4] https://arxiv.org/abs/2006.05525
Published version: International Journal of Computer Vision, 129(6), 1789–1819 (2021).[5]
3. FitNets: Hints for Thin Deep Nets (Romero, Ballas, Kahou, Chassang, Gatta, Bengio, 2015)
— Extends distillation to allow training a student that is deeper and thinner than the teacher, using intermediate representations as hints.[1] https://arxiv.org/abs/1412.6550
4. Born Again Neural Networks (Furlanello, Lipton, Tschannen, Itti, Anandkumar, 2018)
— Studies KD from a new perspective: rather than compressing models, trains students parameterized identically to their teachers.[1] Surprisingly, these Born-Again Networks outperform their teachers significantly.[1] https://arxiv.org/abs/1805.04770
5. Improved Knowledge Distillation via Teacher Assistant (Mirzadeh, Farajtabar, Li, et al., 2020)
— Introduces multi-step knowledge distillation, which employs an intermediate-sized network (teacher assistant) to bridge the gap between the student and the teacher.[1] https://arxiv.org/abs/1902.03393
6. Sequence-Level Knowledge Distillation (Kim, Rush, 2016)
— Demonstrates that standard knowledge distillation applied to word-level prediction can be effective for NMT, and introduces sequence-level versions that further improve performance.[1] https://arxiv.org/abs/1606.07947
7. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (Sanh, Debut, Chaumond, Wolf, 2019)
— Shows it is possible to reduce the size of a BERT model by 40%, while retaining 97% of its language understanding capabilities and being 60% faster.[1] https://arxiv.org/abs/1910.01108
8. Relational Knowledge Distillation (Park, Kim, Lu, Cho, 2019)
— Introduces relational knowledge distillation (RKD), that transfers mutual relations of data examples instead of individual outputs.[1] Proposes distance-wise and angle-wise distillation losses.[1] https://arxiv.org/abs/1904.05068